

지금까지 GPU를 사용하기 위한 환경(플랫폼, 클러서터)을 준비했다면, 이제는 실제 멀티GPU를 사용해보자 (1)
먼저, 이번 페이지에서는 기초강의 중 개론에 대해 짧게 요약하겠습니다.
NVIDIA DLi 세션 내용을 요약하여 전달합니다. 실습환경 및 상세내용을 직접 교육을 수강하기를 추천합니다.
수강한 과정은 NVIDIA Solution Architecture 인 Terry Yin 선생님의 강의
많은 사전 지식을 요구하지 않는 교육이라 쉽게 따라 갈수 있었다. 만약 사전지식이 없더라도, 준비할 시간이 없더라도, 필요한 내용들은 중간중간 다루도록 하겠습니다.


첫 수업은 왜 다중 GPU가 필요한지 부터 단일GPU와 멀티/다중GPU 개요에 대한 설명입니다.

신경망은 새로운 것이 아니다. 놀랄만큼 단순한 알고리즘이나 느린 속도때문에 역사적으로 유효하게 사용되지 않았을 뿐입니다.

그러다가 컴퓨팅 파워의 놀랄만한 발전과 GPU 등장으로 신경망 사용이 활성화되기 시작했습니다.
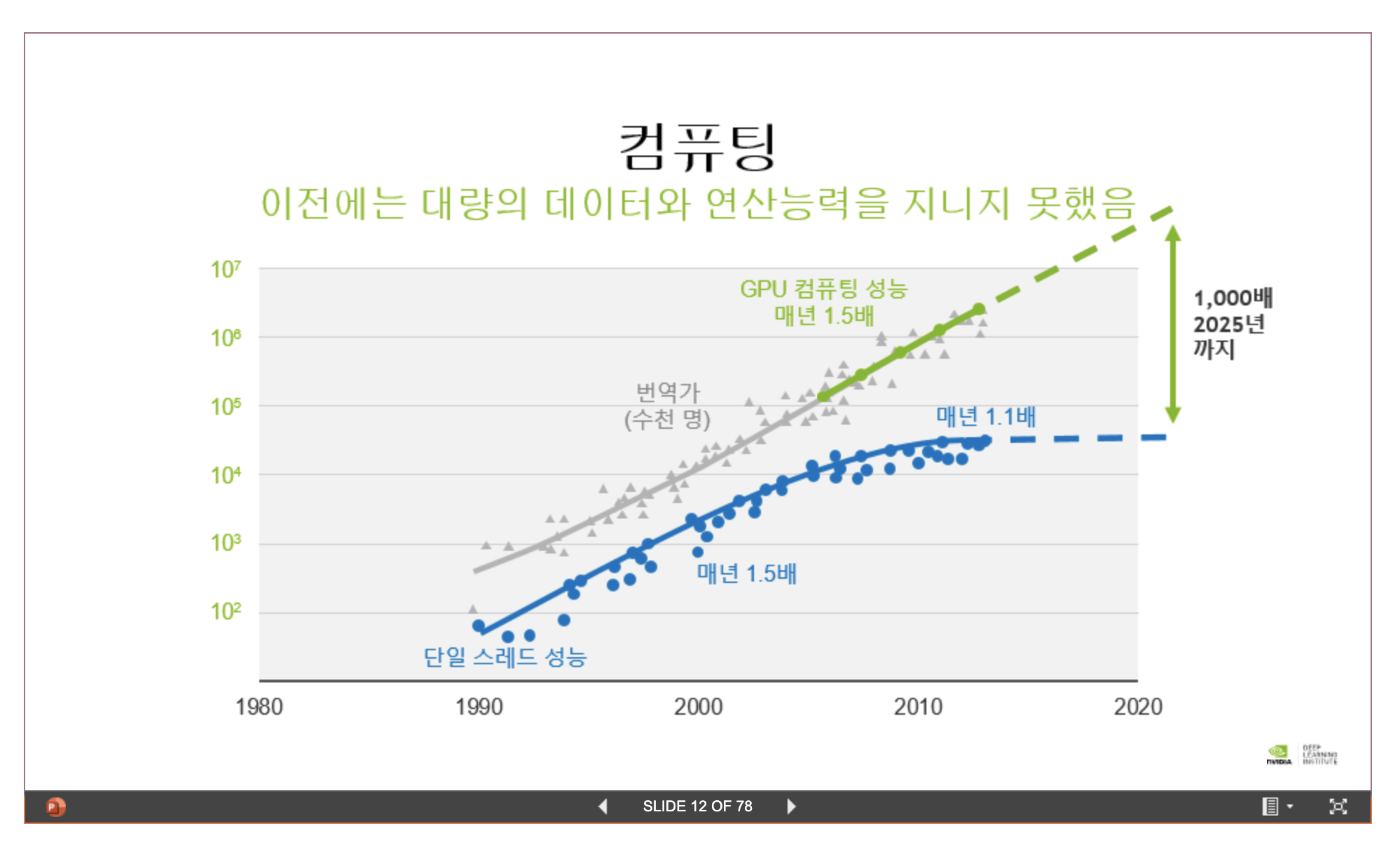
GPU 성능이 대단하다는 것을 단적으로 보여주는 사진입니다.
2009년에 몇백개 서버의 연산성능보다 2019년 DGX-2 서버 1대가 연산력이 커서 2페타 FPLOPs 에 이른다고 합니다.


매번 헷갈리는 엑사와 페타가 약 1000배 차이, 페타는 테라보다 약 1000배 뛰어난 계산능력입니다. .
- 1 000 000 000 000 000 000 = 10^18 엑사 (exa)
- 1 000 000 000 000 000 = 10^15 페타 (peta)
- 1 000 000 000 000 = 10^12 테라 (tera)
- 1 000 000 000 = 10^9 기가 (giga)
- 1 000 000 = 10^6 메가 (mega)


아무래도 기존까지 연산력 부족으로 불가능하던 것들이 GPU 등 하드웨어 개선으로 계산가능해지면서, 필요한 데이터셋도 크게 증가했다고 합니다. AI와 GPU는 거의 모든 분야에서 지각변동 수준의 변화를 불러일으켰습니다.

GPU 등장으로 많은 변화가 있었지만, 세상사가 다 그렇든 좋은 점과 나쁜 점이 존재합니다. 그런데 연구개발에 비용이 크게 상승한다는 것은 개인 혹은 학교 Lab실에서 연구개발 및 실용화, 모델 검증 분야에 한계가 있다는 점을 나타내기도 합니다.

그외 많은 시간을 데이터와 모델 등등 선형적으로 증가한다는 내용이었습니다. 결국, 연산력이 올라갈수록 많은 것을 할수 있게 됐고, 정확도를 높이기 위해 필요한 데이터량 또한 크게 증가했다는 걸로 요약할 수 있습니다.



aze